The following is a sample chapter from my book PACE.
Captain Alex Konarski gazed through the porthole window at the blue mass below. It looked the same as it had for the last nine years. When first informed of the Front, he had half-expected to see a pestilential wall of grey or a glowing force field or some other tell-tale sign. Instead there was nothing, just the same globe that always was there. The same boring old globe.
Konarski remembered the precise time it had taken for her charms to expire. Six months, twelve days. It was the same for every newcomer to the ISS; at first, they gawked at the beauty of Earth and couldn’t shut up about it. Then they did. Konarski always waited a discrete period after each arrival before asking how long it had taken.
Nobody seemed to remember the point at which things changed, they just woke up one day and the magic was gone. How like marriage, he’d laugh, slapping them on the back. By now the joke was well-worn. Of course, it wasn’t just the Earth itself. When somebody new arrived, they acted like a hyperactive puppy, bouncing with delight at each new experience, or perhaps ricocheting was a better choice of word up here.
Once the excitement died down, they discovered it was a job like any other, except that home was a tiny bunk a few feet from where you worked. The tourists had it right: get in and out before the novelty wore off. The ISS basically was a submarine posting with a better view and better toilets.
Earth became something to occasionally note out the corner of one’s eye. Yep, still there. Being so high up almost bred contempt for the tiny ball and its billions of people. This had been less of a problem in the old days, when the ISS sounded like the inside of a factory. But since the upgrade, things were so quiet that one could not help but feel aloof. Aloof was invented for this place. As a general rule, it was hard to hold in high regard any place toward which you flushed your excrement. Well, not quite *toward*.
There was a fun problem in orbital mechanics that Konarski used to stump newbies with. Of course, Alex had learned it in high school, but his colleagues — particularly the Americans — seemed to have spent their formative years doing anything but studying. For some reason, America believed it was better to send jocks into orbit than scientists. Worse even, it made a distinction between the two. Nerds are nerds and jocks are jocks and never the twain shall meet. It was a view that Konarski and most of the older generation of Eastern Europeans found bewildering. But that was the way it was.
So, Alex and his friends gave the newbies the infamous “orbit” problem. If you are working outside the ISS and fling a wrench toward Earth what will happen? Invariably, the response was to the effect that “well, duh, it will fall to Earth”. With carefully practiced condescension, Alex then would inform them that this is not correct. The wrench will rebound and hit the pitcher. It was one of the many vagaries of orbital dynamics, unintuitive but fairly obvious on close reflection.
The victim would argue, debate, complain, declare it an impossibility. Alex patiently would explain the mathematics. It was no mistake. Only after the victim had labored for days over a calculation that any kid should be able to do would they — sometimes — get the answer.
For some reason the first question they asked after accepting the result always was, “How do you flush the toilets?”
“Very carefully,” Alex would answer.
Then everybody had a drink and a good laugh. Yes, shit would fall to earth just as it always had and always would.
The spectrometer indicated that there was some sort of smog developing over Rome. Alex wondered if this would be a repeat of Paris. There had been sporadic fires for weeks after the Front hit that city. Some were attributable to the usual suspects: car crashes as people fled or died, overloads and short-circuits, the chaos of large numbers of people fleeing, probably even arson, not to mention the ordinary incidence of fires in a major city, now with nobody to nip them in the bud. Mostly, though, it just was the unattended failure of humanity’s mechanized residue.
The Front couldn’t eradicate every trace of our existence, but perhaps it would smile gleefully as our detritus burned itself out. Those last embers likely would outlast us, a brief epitaph. Of course, the smaller fires weren’t visible from the station, and Alex only could surmise their existence from the occasional flare up.
The same had occurred everywhere else the Front passed. In most cases there had been a small glow for a day or so and then just the quenching smoke from a spent fire. On the other hand, there was a thick haze over parts of Germany since fires had spread through the coal mines. These probably would burn for years to come, occasionally erupting from the ground without warning. There was no need to speculate on *that*; Konarski’s own grandfather had perished this way many years ago. The mines had been killing people long before there was any Front. But the occasional fireworks aside, cities inside the Zone were cold and dead.
The ISS orbited the Earth approximately once every ninety minutes. This meant that close observation of any given area was limited to a few minutes, after which they must wait until the next pass. During the time between passes, the Front would expand a little over a quarter mile. Nothing remarkable had happened during the hundred passes it took for the Front to traverse Paris. And it wasn’t for another twenty or so that the trouble started.
*Trouble?* Something about the word struck him as callous. It seemed irreverent to call a fire “trouble”, while ignoring the millions of deaths which surely preceded it. Well, the “event”, then. Once it started, the event was evident within a few passes. Alex had noticed something wrong fairly quickly. Instead of a series of small and short-lived flare ups, the blaze simply had grown and grown.
At first he suspected the meltdown of some unadvertised nuclear reactor. But there was no indication of enhanced radiation levels. Of course, it was hard to tell for sure through the smoke plume. By that point it looked like there was a small hurricane over Paris, a hurricane that occasionally flashed red. It really was quite beautiful from his vantage point, but he shuddered to think what it would be like within that mile-high vortex of flame.
It had not ceased for seven days. Some meteorologist explained the effect early on. It was called a firestorm, when countless small fires merge into a monster that generates its own weather, commands its own destiny. It was a good thing there was nobody left for it to kill, though Alex was unsure what effect the fountain of ash would have on the rest of Europe.
In theory there probably were operational video feeds on the ground, but the Central European power grid had failed two months earlier. It had shown surprisingly little resilience, and shrouded most of Europe in darkness. Of course, the relevant machinery lay within the Zone and repairs were impossible.
Konarski wondered how many millions had died prematurely because some engineering firm cut corners years ago. It probably was Ukrainian, that firm. Alex never trusted the Ukrainians. Whatever the cause, the result was that there was no power. And by the time Paris was hit any battery-driven units were long dead. Other than some satellites and the occasional drone, he and his crew were the only ones to see what was happening.
The Paris conflagration eventually had withered and died out, of course. What was of interest now was Rome. The ISS had been asked to keep an eye on the regions within the Zone, gleaning valuable information to help others prepare or, if one were fool enough to hope, understand and dispel the Front altogether. However, the real action always surrounded the Front itself. Especially when it hit a densely-developed area, even if now deserted. But it wasn’t just orders or morbid curiosity that compelled Alex to watch. Where evident, the destruction could be aesthetically beautiful.
Safely beyond the reach of the Front, Alex could watch the end of a world. How many people would have the opportunity to do so? There was a certain pride in knowing he would be among the last, perhaps even *the* last. Once everyone had perished, the crew of the ISS would be alone for a while, left to contemplate the silence. Then their supplies would run out, and they too would die.
Based on the current consumption rate of his six person crew, Alex estimated they could survive for another six years — two years past the Front’s anticipated circumvallation of Earth. Of course, he doubted the process would be an orderly one. Four of the crew members (himself included) came from military backgrounds, one was a woman, and three different countries were represented. Even at the best of times, there was a simmering competitiveness.
Konarski assumed that he would be the first casualty. No other scenario made sense, other than something random in the heat of passion — and such things didn’t require the Front. No, barring any insanity, he would go first. He was the leader and also happened to be bedding the only woman. Who else would somebody bother killing? Of course, with *this* woman, he shuddered to think what would happen to the murderer. Of course, *she* was the one most likely to kill him in the first place.
Obviously, they hadn’t screened for mental health in the Chinese space program. In fact, he guessed that any screening they *did* do was just lip-service to be allowed to join the ISS. But Ying was stunning and endlessly hilarious to talk to, and Alex had nothing to lose.
If the Front hadn’t come along, he would have faced compulsory retirement the following year. Then he would have had the privilege of returning to good old Poland, a living anachronism in a country that shunned any sign of its past. Alex gave it about a year before the bottle would have taken him. Who the fuck wanted to grow old in today’s world? The Front was the best thing that ever happened, as far as he was concerned. It made him special.
Alex would try to protect Ying for as long as he could, but he knew how things would unfold. Perhaps it would be best to kill her first, before anyone got to him. Or maybe he just should suicide the whole crew. It would be the easiest thing in the world, all he really had to do was stop trying to keep everyone alive. Or he actively could space the place and kill everyone at once, a grand ceremonial gesture. But that would be boring.
Besides, part of him wanted to see who *would* be the last man standing. The whole of humanity in one man. The one to turn out the lights, not first but final hand. Humanity would end the way it began, with one man killing another. After all, everybody always was talking about returning to your roots. Alex just was sad they no longer had a gun on board. That *really* would have made things interesting.
These were distant considerations, however; worth planning for, but hardly imminent. At the moment the world remained very much alive, and was counting on them for critical information. Alex wondered if it would be better to be the last man alive or the man who saved the world.
“The savior, you dumb fuck,” part of him screamed. “Nobody will be around to care if you’re the last one alive.” Of course, Poland already was gone. There was no home for him, even the one he wouldn’t have wanted. Maybe he was the last Pole. But how would he change a light bulb?
For some reason, a series of bad Pollack jokes popped into Konarski’s head. There was a time when he would have taken great offense at such jokes, jumped to his country’s defense, maybe even thrown a few obligatory punches. But not now, not after what Poland had become over the last decade, and especially not after how they had behaved toward the end. They could go fuck themselves. And now they had. Or somebody bigger and badder had fucked them, just like had happened through most of their history.
Still, he felt a certain pride. Maybe he would be the start of a new, prouder race of Poles. No, that was just the sort of talk that had made him sick of his country, the reason he was commanding ISS under a Russian flag. Besides, there probably still were plenty of Poles around the world. He wasn’t alone. Yet.
If Alex watched Rome’s demise closely, he couldn’t be accused of exultation or cruel delight. He had watched his home city of Warsaw perish just three days earlier. Of course, it was nearly empty by the time the Front reached it. But he had listened to the broadcasts, the chatter, and he was ashamed of the conduct of his countrymen. They had acted just like the self-absorbed Western pigs he detested.
Ying understood. She was Chinese. When *they* left their old and infirm behind it would be from calculated expedience, not blind selfish panic. The decision would be institutional, not individual. The throng would push and perish and each would look to their own interest, but none would bear the individual moral responsibility. *That* would be absorbed by the State. What else was the State for?
But it turned out that his compatriots no longer thought this way. They had become soft since the fall of communism, soft and scared. When the moment came, they didn’t stand proud and sink with the ship. They scrambled over one another like a bunch of terrified mice, making a horrid mess and spitting on the morals of their homeland and a thousand years of national dignity just to buy a few more precious moments of lives clearly not worth living. They disgusted him. He would die the last true Pole.
In the meantime, he would carry on — his duty now to the species. Part of him felt that if *his* world had perished, so too should all the others. He harbored a certain resentment when he imagined some American scientists discovering the answer just in time to save their own country. It would be *his* data that accomplished this. What right had they to save themselves using *his* data, when his own people had perished. Yet still he sent it. Data that perhaps would one day allow another world to grow from the ashes of his. Maybe this was a sign that there *had* been some small progress over the thousands of years, that he was first and foremost human.
Alex’s thoughts were interrupted by a soft voice.
“We’re almost over Rome,” Ying whispered, breathing gently into his ear.
“C’mon, I have to record this,” he protested in half-genuine exasperation.
“That’s ok, we’ll just catch the next pass,” she shot back from behind him.
Alex heard some shuffling and felt something strange on his shoulder. What was Ying doing now? He had to focus, dammit. She was the funnest, craziest woman he had known, but sometimes he just wished he could lock her outside the station for a few hours. Yeah, he’d probably ask her to marry him at some point. Maybe soon. After all, living with somebody on the ISS was ten times more difficult than being married. Alex shook his shoulder free of her grip. It would have to wait.
Then he noticed that she wasn’t touching him. She was on the other side of the room, pointing at him with her mouth open. Why was there no sound? Then he was screaming, then he couldn’t scream anymore. Before things grew dark, he saw Ying’s decaying flesh. She still was pointing, almost like a mannequin. His last thought was how disgusting Ying had become, and that he soon would be the same.
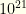 unconstrained fantasy teams, ultimately evaluating under
unconstrained fantasy teams, ultimately evaluating under 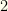 million plausible teams and executing in under
million plausible teams and executing in under 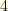 seconds on a relatively modest desktop computer.
seconds on a relatively modest desktop computer. 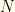 of players which constitute a fantasy team. A fantasy team must have precisely this number of players.
of players which constitute a fantasy team. A fantasy team must have precisely this number of players.
 players from one position and
players from one position and 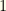 each from
each from  players on a team, with specified positions P,P,C,1B,2B,3B,SS,OF,OF,OF. Salary cap is $50K. Constraints: (1)
players on a team, with specified positions P,P,C,1B,2B,3B,SS,OF,OF,OF. Salary cap is $50K. Constraints: (1) 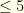 hitters (non-P players) from a given real team, and (2) players from
hitters (non-P players) from a given real team, and (2) players from 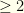 different real games must be present.
different real games must be present.
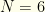 players, with no position requirements. Salary cap is $50K. Constraints: (1) players from
players, with no position requirements. Salary cap is $50K. Constraints: (1) players from  hitters from any one team.
hitters from any one team.
 hitters (non-P players) from a given real team, and (2) players from
hitters (non-P players) from a given real team, and (2) players from 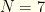 players, with 2 pitchers and 5 hitters. Salary cap is $50K. Constraints are: (1)
players, with 2 pitchers and 5 hitters. Salary cap is $50K. Constraints are: (1) 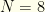 players, with 2 pitchers and 6 hitters. $50K salary cap. Constraints are: (1)
players, with 2 pitchers and 6 hitters. $50K salary cap. Constraints are: (1)  such teams (for some
such teams (for some  groups. It is easy to see that the
groups. It is easy to see that the 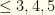 hitter per team constraints fit this mold.
hitter per team constraints fit this mold.
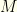 players, listed in some fixed order for our purposes.
players, listed in some fixed order for our purposes. 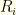 denotes player
denotes player  in our listing.
in our listing.
 of games represented in the given tournament. This would be all the games played on a given day. Almost every team plays each day of the season, so this is around 15 games. We’ll ignore the 2nd game of doubleheaders for our purposes (so a given team and player plays at most once on a given day).
of games represented in the given tournament. This would be all the games played on a given day. Almost every team plays each day of the season, so this is around 15 games. We’ll ignore the 2nd game of doubleheaders for our purposes (so a given team and player plays at most once on a given day).
 of teams represented in the given tournament. This would be all 30 teams.
of teams represented in the given tournament. This would be all 30 teams.
 of length
of length 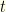 of length
of length 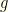 of length
of length  of length
of length  of length
of length  of length
of length 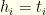 if player
if player 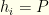 if a pitcher, where
if a pitcher, where  designates some new value not in
designates some new value not in 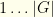 , the teams from
, the teams from  , and the positions from
, and the positions from 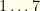 . We’ll assign
. We’ll assign 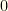 to the pitcher category in the
to the pitcher category in the 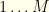 . The vectors
. The vectors 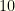
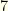 groups (the positions), and marked as a partition.
groups (the positions), and marked as a partition.
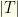 groups (the teams), and marked as a partition.
groups (the teams), and marked as a partition.
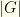 groups (the games), and marked as a partition.
groups (the games), and marked as a partition.
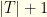 groups (the teams for hitters plus a single group of all pitchers), and marked as a partition.
groups (the teams for hitters plus a single group of all pitchers), and marked as a partition.
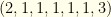 (i.e. P,P,C,1B,2B,3B,SS,OF,OF,OF)
(i.e. P,P,C,1B,2B,3B,SS,OF,OF,OF)
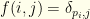 (i.e.
(i.e.  )
)
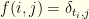 (i.e.
(i.e.  (i.e.
(i.e.  (i.e.
(i.e.  )
)
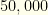
 items in any one group of Feature 4. (i.e.
items in any one group of Feature 4. (i.e. 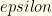 . For a given group, we do this as follows. Assume that we are required to select
. For a given group, we do this as follows. Assume that we are required to select  and value
and value 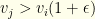
 then we cull item
then we cull item 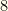 groups with (
groups with ( ,
,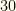 ,
,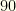 ,
, ) allowed items. We need to select
) allowed items. We need to select 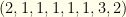 items from amongst these. In reality, fantasy baseball tournaments with flex groups have fewer other groups — so the size isn’t quite this big. But for other Fantasy Sports it can be.
items from amongst these. In reality, fantasy baseball tournaments with flex groups have fewer other groups — so the size isn’t quite this big. But for other Fantasy Sports it can be. 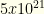 . Suppose we can prune just 1/3 of the players (evenly, so 30 becomes 20, 60 becomes 40, and 90 becomes 60). This reduces the state space by 130x to around
. Suppose we can prune just 1/3 of the players (evenly, so 30 becomes 20, 60 becomes 40, and 90 becomes 60). This reduces the state space by 130x to around 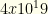 . If we can prune 1/2 the players, we reduce it by
. If we can prune 1/2 the players, we reduce it by  to around
to around  . And if we can prune it by 2/3 (which actually is not as uncommon as one would imagine, especially if many items have
. And if we can prune it by 2/3 (which actually is not as uncommon as one would imagine, especially if many items have  to a somewhat less unmanageable starting point of
to a somewhat less unmanageable starting point of 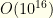 .
.  operations (it doesn’t), where
operations (it doesn’t), where 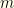 is the non-flex group size and
is the non-flex group size and  which is
which is 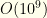 operations. In reality it would be far lower. So a careful cull is well worth it!
operations. In reality it would be far lower. So a careful cull is well worth it! . If it is set too high, we will cull too few items and waste time down the road. If it is too low, we may run into problems meeting the ancillary constraints.
. If it is set too high, we will cull too few items and waste time down the road. If it is too low, we may run into problems meeting the ancillary constraints. 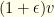 and cost
and cost  in order to cull an item with value
in order to cull an item with value  to reflect this. If
to reflect this. If  is the number of selected items for group
is the number of selected items for group  strictly better items. Note that
strictly better items. Note that 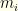 is the total number of items in the
is the total number of items in the  group. Some of the same items may be available to multiple groups, but our collection must consist of distinct items. So there are
group. Some of the same items may be available to multiple groups, but our collection must consist of distinct items. So there are  bins, the number of primary feature groups. For the
bins, the number of primary feature groups. For the  possible selections. We can precompute this easily enough.
possible selections. We can precompute this easily enough.
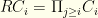 . I.e. the product of the total combinations of this group and those that come after.
. I.e. the product of the total combinations of this group and those that come after.
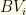 is the sum of the top
is the sum of the top 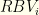 is
is  . I.e., the best total value we can get from all subsequent groups.
. I.e., the best total value we can get from all subsequent groups.
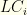 is the sum of the bottom
is the sum of the bottom  is
is  . I.e., the cheapest we can do for all subsequent groups, if value is no concern.
. I.e., the cheapest we can do for all subsequent groups, if value is no concern.
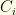 ) or from most to fewest (high to low
) or from most to fewest (high to low 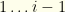 ). We also are given
). We also are given  , the lowest collection value we will consider. We’ll discuss how this is obtained shortly.
, the lowest collection value we will consider. We’ll discuss how this is obtained shortly.  sorted by value or by cost depending on our 2nd choice above. I.e., we are iterating over the possible selections of
sorted by value or by cost depending on our 2nd choice above. I.e., we are iterating over the possible selections of 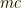 is the minimum cost of all remaining groups (
is the minimum cost of all remaining groups (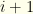 onward). This is the lowest cost we possibly could achieve for subsequent groups. It is the pre-computed
onward). This is the lowest cost we possibly could achieve for subsequent groups. It is the pre-computed  is the maximum value of all remaining groups (
is the maximum value of all remaining groups ( is the cost of our current selection for group
is the cost of our current selection for group 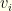 is the value of our current selection for group
is the value of our current selection for group  then there is no way to select from the remaining groups and meet the cost cap. Worse, all remaining iterations within group
then there is no way to select from the remaining groups and meet the cost cap. Worse, all remaining iterations within group  then there is no way to select a high enough value collection from the remaining groups. However, it is possible that other iterations may do so (since we’re iterating by cost, not value). We prune just the current selection, and move on to the next combo in group
then there is no way to select a high enough value collection from the remaining groups. However, it is possible that other iterations may do so (since we’re iterating by cost, not value). We prune just the current selection, and move on to the next combo in group  and value
and value 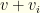 and group
and group 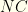 . We need to maintain a value-sorted list of our top collections in a queue-like structure.
. We need to maintain a value-sorted list of our top collections in a queue-like structure. 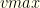 , the best value realized, This also resets
, the best value realized, This also resets 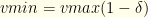 for some user-defined tolerance
for some user-defined tolerance  . We then must drop any already-accumulated collections which fall below the new
. We then must drop any already-accumulated collections which fall below the new ![{\epsilon\in [0,\infty]}](https://s0.wp.com/latex.php?latex=%7B%5Cepsilon%5Cin+%5B0%2C%5Cinfty%5D%7D&bg=fefeeb&fg=000000&s=0&c=20201002) ?
?
 we report back (or do we keep them all)?
we report back (or do we keep them all)?
![{\delta\in [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cdelta%5Cin+%5B0%2C1%5D%7D&bg=fefeeb&fg=000000&s=0&c=20201002) ?
?
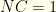 or
or  will do. As mentioned,
will do. As mentioned, 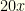 . There is good reason to believe that, for any common tournament structure, the results would be consistent once established. It also is likely they will reflect these. Why? The fastest option allows the most aggressive pruning early in the process. That’s why so few collections needed to be analyzed.
. There is good reason to believe that, for any common tournament structure, the results would be consistent once established. It also is likely they will reflect these. Why? The fastest option allows the most aggressive pruning early in the process. That’s why so few collections needed to be analyzed. 