I’ve recently been reviewing Bayesian networks with an eye to learning STAN. One question which occurred to me is the following. Suppose we are interested in the probability distribution 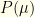 over parameters
over parameters 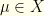 (with state space
(with state space  ). We acquire some data
). We acquire some data  , and wish to use it to infer . Note that refers to the specific realized data, not the event space from which it is drawn.
, and wish to use it to infer . Note that refers to the specific realized data, not the event space from which it is drawn.
Let’s assume that (1) we have a prior , (2) the likelihood  is easy to compute or sample, and (3) the normalization
is easy to compute or sample, and (3) the normalization 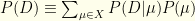 is not expensive to compute or adequately approximate.
is not expensive to compute or adequately approximate.
The usual Bayesian approach involves updating the prior to a posterior via Bayes’ thm:  . However, there also is another view we may take. We need not restrict ourselves to a single Bayesian update. It is perfectly reasonable to ask whether multiple updates using the same would yield a more useful result.
. However, there also is another view we may take. We need not restrict ourselves to a single Bayesian update. It is perfectly reasonable to ask whether multiple updates using the same would yield a more useful result.
Such a tactic is not as ridiculous or unjustified as it first seems. In many cases, the Bayesian posterior is highly sensitive to a somewhat arbitrary choice of prior . The latter frequently is dictated by practical considerations rather than arising naturally from the problem at hand. For example, we often use the likelihood function’s conjugate prior to ensure that the posterior will be of the same family. Even in this case, the posterior depends heavily on the precise choice of .
Though we must be careful interpreting the results, there very well may be applications in which an iterated approach is preferable. For example, it is conceivable that multiple iterations could dilute the dependence on , emphasizing the role of instead. We can seek inspiration in the stationary distributions of Markov chains, where the choice of initial distribution becomes irrelevant. As a friend of mine likes to say before demolishing me at chess: let’s see where this takes us. Spoiler: infinite iteration “takes us” to maximum-likelihood selection.
An iterated approach does not violate any laws of probability. Bayes’ thm is based on the defining property  . Our method is conceptually equivalent to performing successive experiments which happen to produce the same data each time, reinforcing our certainty around it. Although its genesis is different, the calculation is the same. I.e., any inconsistency or inapplicability must arise through interpretation rather than calculation. The results of an iterated calculation may be inappropriate for certain purposes (such as estimating error bars, etc), but could prove useful for others.
. Our method is conceptually equivalent to performing successive experiments which happen to produce the same data each time, reinforcing our certainty around it. Although its genesis is different, the calculation is the same. I.e., any inconsistency or inapplicability must arise through interpretation rather than calculation. The results of an iterated calculation may be inappropriate for certain purposes (such as estimating error bars, etc), but could prove useful for others.
In fact, one could argue there only are two legitimate approaches when presented with a one-time data set . We could apply it once or an infinite number of times. Anything else would amount to an arbitrary choice of the number of iterations.
It is easy to analyze the infinite iteration process. For simplicity, we’ll consider the case of a discrete, finite state space . is a fixed set of data values for our problem, so we are not concerned with the space or distribution from which it is drawn. 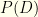 is a derived normalization factor, nothing more.
is a derived normalization factor, nothing more.
Let’s introduce some notation:
– Let  , and denote the elements of by
, and denote the elements of by  .
.
– We could use 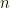 -vectors to denote probability or conditional probability distributions over (with the
-vectors to denote probability or conditional probability distributions over (with the  component the probability of
component the probability of 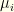 ), but it turns out to be simpler to use diagonal
), but it turns out to be simpler to use diagonal  matrices.
matrices.
– is an -vector, which we’ll write as a diagonal matrix  with
with  .
.
– We’ll denote by  the data set repeated
the data set repeated  times. I.e., the equivalent of having performed an experiment times and obtained each time.
times. I.e., the equivalent of having performed an experiment times and obtained each time.
– 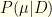 is an -vector, which we’ll write as a diagonal matrix
is an -vector, which we’ll write as a diagonal matrix 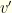 with
with 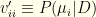 ).
).
– Where multiple updates are involved, we denote the final posterior  via an diagonal matrix
via an diagonal matrix  , with
, with 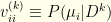 . Note that
. Note that  and
and  .
.
– as an -vector of probabilities as well, but we’ll also treat it as a diagonal matrix 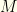 with
with  .
.
–  is a scalar. In our notation,
is a scalar. In our notation, 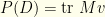 .
.
A single Bayesian update takes the form  . What happens if we repeat this? A second iteration substitutes for , and we get
. What happens if we repeat this? A second iteration substitutes for , and we get  . This is homogeneous of degree
. This is homogeneous of degree 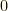 in , so the
in , so the  normalization factor in disappears. We thus have
normalization factor in disappears. We thus have 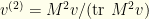 . The same reasoning extends to
. The same reasoning extends to 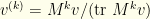 .
.
It now is easy to see what is happening. Suppose  , and let
, and let  . Our expression for
. Our expression for  after iterations is
after iterations is 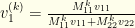 .
.
This has the form 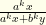 , which can be written
, which can be written 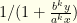 . We know that
. We know that  , so as long as
, so as long as 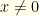 we have
we have 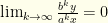 . Specifically, for
. Specifically, for  we have
we have  for
for 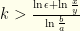 . Note that the denominator is negative since
. Note that the denominator is negative since 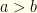 and the numerator is negative for small enough
and the numerator is negative for small enough  .
.
We therefore have shown that (in this simple case), 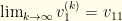 . If we perform the same analysis for
. If we perform the same analysis for  , we get
, we get 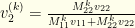 , which corresponds to
, which corresponds to 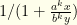 . The denominator diverges for large enough , and the limit is . We therefore see that
. The denominator diverges for large enough , and the limit is . We therefore see that 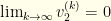 .
.
This trivially extends to  . As
. As 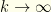 , all but the dominant
, all but the dominant  are exponentially suppressed. The net effect of infinite iteration is to pick out the maximum likelihood value. I.e., we select the corresponding to the maximum . All posterior probability is concentrated in that. Put another way, the limit of iterated posteriors is
are exponentially suppressed. The net effect of infinite iteration is to pick out the maximum likelihood value. I.e., we select the corresponding to the maximum . All posterior probability is concentrated in that. Put another way, the limit of iterated posteriors is  for
for 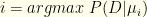 and for all others.
and for all others.
What if the maximum is degenerate? Let’s again consider the simple case, but now with 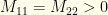 . It is easy to see what happens in this case.
. It is easy to see what happens in this case. 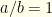 , so
, so  and
and  . Note that
. Note that  here, but we stated the denominator explicitly to facilitate visualization of the extension to .
here, but we stated the denominator explicitly to facilitate visualization of the extension to .
This extension is straightforward. We pick out the maximum likelihood values , and they are assigned their prior probabilities, renormalized. Suppose there are  degenerate maximum ‘s, with indices
degenerate maximum ‘s, with indices 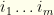 (each
(each 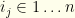 ). The limit of iterated posteriors
). The limit of iterated posteriors  . This reduces to our previous result when
. This reduces to our previous result when 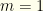 .
.
Note that we must ensure 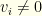 for the maximum likelihood ‘s. I.e., we cannot have a prior for any of the maximum likelihood values. If we wish to exclude ‘s from consideration, we should do so before the calculation, thus eliminating the corresponding
for the maximum likelihood ‘s. I.e., we cannot have a prior for any of the maximum likelihood values. If we wish to exclude ‘s from consideration, we should do so before the calculation, thus eliminating the corresponding  ‘s from contention for the maximum likelihood.
‘s from contention for the maximum likelihood.
Expanding 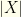 to a countable set poses no problem. In the continuous case, we must work with intervals (or measurable sets) rather than point values. For any and any set of nonzero measure containing all the maximum likelihood values, there will be some that concentrates all but of the posterior probability in that set.
to a countable set poses no problem. In the continuous case, we must work with intervals (or measurable sets) rather than point values. For any and any set of nonzero measure containing all the maximum likelihood values, there will be some that concentrates all but of the posterior probability in that set.
Note that depends on the choice of measurable set, and care must be taken when considering limits of such sets. For example, let  be the maximum likelihood probability. If we consider an interval
be the maximum likelihood probability. If we consider an interval  as our maximum likelihood set, then the maximum likelihood “value” is the (measurable) set
as our maximum likelihood set, then the maximum likelihood “value” is the (measurable) set  . For any , we have a as discussed above, such that
. For any , we have a as discussed above, such that 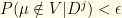 for
for 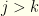 . However, for a fixed , that will vary with
. However, for a fixed , that will vary with  . Put another way, we cannot simply assume uniform convergence.
. Put another way, we cannot simply assume uniform convergence.
We can view infinite iteration as a modification of the prior. Specifically, it is tantamount to pruning the prior of all non-maximum-likelihood values and renormalizing it accordingly. The posterior then is equal to the prior under subsequent single- steps (i.e. it is a fixed point distribution). Alternatively, we can view the whole operation as a single  update. In that case, we keep the original prior and view the posterior as the aforementioned pruned version of the prior.
update. In that case, we keep the original prior and view the posterior as the aforementioned pruned version of the prior.
There are two takeaways here:
1. The infinite iteration approach simply amounts to maximum-likelihood selection. It selects the maximum likelihood value(s) from the known and maintains their relative prior probabilities, suitably renormalized. Equivalently, it prunes all the non-maximum-likelihood values.
2. The resulting posterior still depends on the choice of prior unless the maximum likelihood value is unique, in which case that value has probability  .
.
Unlike stationary distributions of Markov chains, the result is not guaranteed to be independent of our arbitrary initial choice — in this case, the prior . Though true independence only is achieved when there is a unique maximum likelihood value, the dependence is reduced significantly even when there is not. The posterior depends only on those prior values corresponding to maximum likelihood 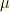 ‘s. All others are irrelevant. The maximum likelihood values typically form a tiny subset of ‘s, thus eliminating most dependence on the prior. Note that such degeneracy (as well as the values themselves) is solely determined by the likelihood function.
‘s. All others are irrelevant. The maximum likelihood values typically form a tiny subset of ‘s, thus eliminating most dependence on the prior. Note that such degeneracy (as well as the values themselves) is solely determined by the likelihood function.
