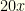While toying with automated Fantasy Sports trading systems, I ended up designing a rapid state search algorithm that was suitable for a variety of constrained knapsack-like problems.
A reference implementation can be found on github: https://github.com/kensmosis/ccsearch.
Below is a discussion of the algorithm itself. For more details, see the source code in the github repo. Also, please let me know if you come across any bugs! This is a quick and dirty implementation.
Here is a description of the algorithm:
— Constrained Collection Search Algorithm —
Here, we discuss a very efficient state-space search algorithm which originated with a Fantasy Sports project but is applicable to a broad range of applications. We dub it the Constrained Collection Search Algorithm for want of a better term. A C++ implementation, along with Python front-end is included as well.
In the Fantasy Sports context, our code solves the following problem: We’re given a tournament with a certain set of rules and requirements, a roster of players for that tournament (along with positions, salaries and other info supplied by the tournament’s host), and a user-provided performance measure for each player. We then search for those teams which satisfy all the constraints while maximizing team performance (based on the player performances provided). We allow a great deal of user customization and flexibility, and currently can accommodate (to our knowledge) all major tournaments on Draftkings and FanDuel. Through aggressive pruning, execution time is minimized.
As an example, on data gleaned from some past Fantasy Baseball tournaments, our relatively simple implementation managed to search a state space of size approximately 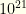
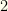
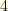
Although originating in a Fantasy Sport context, the CCSearch algorithm and code is quite general.
— Motivating Example —
We’ll begin with the motivating example, and then consider the more abstract case. We’ll also discuss some benchmarks and address certain performance considerations.
In Fantasy Baseball, we are asked to construct a fantasy “team” from real players. While the details vary by platform and tournament, such games share certain common elements:
- A “roster”. This is a set of distinct players for the tournament.
- A means of scoring performance of a fantasy team in the tournament. This is based on actual performance by real players in the corresponding games. Typically, each player is scored based on certain actions (perhaps specific to their position), and these player scores then are added to get the team score.
- For each player in the roster, the following information (all provided by the tournament host except for the predicted fantasy-points, which generally is based on the user’s own model of player performance):
- A “salary”, representing the cost of inclusion in our team.
- A “position” representing their role in the game.
- One or more categories they belong to (ex. pitcher vs non-pitcher, real team they play on).
- A prediction of the fantasy-points the player is likely to score.
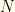 of players which constitute a fantasy team. A fantasy team must have precisely this number of players.
of players which constitute a fantasy team. A fantasy team must have precisely this number of players.
 players from one position and from another and
players from one position and from another and 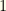 each from other positions. Sometimes there are “flex” positions, and we’ll discuss how to accommodate those as well. The total players in all the positions must sum to .
each from other positions. Sometimes there are “flex” positions, and we’ll discuss how to accommodate those as well. The total players in all the positions must sum to .
To give a clearer flavor, let’s consider a simple example: Draftkings Fantasy Baseball. There are at least 7 Tournament types listed (the number and types change with time, so this list may be out of date). Here are some current game types. For each, there are rules for scoring the performance of players (depending on whether hitter or pitcher, and sometimes whether relief or starting pitcher — all of which info the tournament host provides):
- Classic:
players on a team, with specified positions P,P,C,1B,2B,3B,SS,OF,OF,OF. Salary cap is $50K. Constraints: (1)
hitters (non-P players) from a given real team, and (2) players from
different real games must be present.
- Tiers:
- Showdown:
players, with no position requirements. Salary cap is $50K. Constraints: (1) players from
hitters from any one team.
- Arcade:
hitters (non-P players) from a given real team, and (2) players from
- Playoff Arcade:
players, with 2 pitchers and 5 hitters. Salary cap is $50K. Constraints are: (1)
- Final Series (involves 2 games):
players, with 2 pitchers and 6 hitters. $50K salary cap. Constraints are: (1)
- Lowball: Same as Tiers, but the lowest score wins.
Although the constraints above may seem quite varied, we will see they fall into two easily-codified classes.
In the Classic tournament, we are handed a table prior to the competition. This contains a roster of available players. In theory there would be 270 (9 for each of the 30 teams), but not every team plays every day and there may be injuries so it can be fewer in practice. For each player we are given a field position (P,C,1B,2B,3B,SS,or OF), a Fantasy Salary, their real team, and which games they will play in that day. For our purposes, we’ll assume they play in a single game on a given day, though it’s easy to accommodate more than one.
Let us suppose that we have a model for predicting player performance, and are thus also provided with a mean and standard deviation performance. This performance is in terms of “points”, which is Draftkings’ scoring mechanism for the player. I.e., we have a prediction for the score which Draftkings will assign the player using their (publicly available) formula for that tournament and position. We won’t discuss this aspect of the process, and simply take the predictive model as given.
Our goal is to locate the fantasy teams which provide the highest combined predicted player scores while satisfying all the requirements (position, salary, constraints) for the tournament. We may wish to locate the top 
Note that we are not simply seeking a single, best solution. We may wish to bet on a set of 20 teams which diversify our risk as much as possible. Or we may wish to avoid certain teams in post-processing, for reasons unrelated to the constraints.
It is easy to see that in many cases the state space is enormous. We could attempt to treat this as a knapsack problem, but the desire for multiple solutions and the variety of constraints make it difficult to do so. As we will see, an aggressively pruned direct search can be quite efficient.
— The General Framework —
There are several good reasons to abstract this problem. First, it is the sensible mathematical thing to do. It also offers a convenient separation from a coding standpoint. Languages such as Python are very good at munging data when efficiency isn’t a constraint. However, for a massive state space search they are the wrong choice. By providing a general wrapper, we can isolate the state-space search component, code it in C++, and call out to execute this as needed. That is precisely what we do.
From the Fantasy Baseball example discussed (as well as the variety of alternate tournaments), we see that the following are the salient components of the problem:
- A cost constraint (salary sum)
- The number of players we must pick for each position
- The selection of collections (teams) which maximize the sum of player performances
- The adherence to certain constraints involving player features (hitter/pitcher, team, game)
Our generalized tournament has the following components:
- A number of items
- A total cost cap for the
- A set of items, along with the following for each:
- A cost
- A mean value
- Optionally, a standard deviation value
- A set of features. Each feature has a set of values it may take, called “groups” here. For each feature, a table (or function) tells us which group(s), if any, each item is a member of. If every item is a member of one and only one group, then that feature is termed a “partition” for obvious reasons.
- A choice of “primary” feature, whose role will be discussed shortly. The primary feature need not be a partition. Associated with the primary feature is a count for each group. This represents the number of items which must be selected for that group. The sum of these counts must be
- A set of constraint functions. Each takes a collection and, based on the information above, accepts or rejects it. We will refer to these as “ancillary constraints”, as opposed to the overall cost constraint, the primary feature group allocation constraints, and the number of items per collection constraint. When we speak of “constraints” we almost always mean ancillary constraints.
To clarify the connection to our example, the fantasy team is a collection, the players are items, the cost is the salary, the value is the performance prediction, the primary feature is “position” (and its groups are the various player positions), other features are “team” (whose groups are the 30 real teams), “game” (whose groups are the real games being played that day), and possibly one or two more which we’ll discuss below.
Note that each item may appear only once in a given collection even if they theoretically appear can fill multiple positions (ex. they play in two games of a double-header or they are allowed for a “flex” position as well as their actual one in tournaments which have such things).
Our goal at this point will be to produce the top
It is important to note that features need not be partitions. This is true even of the primary feature. In some tournaments, for example, there are “utility” or “flex” positions. Players from any other position (or some subset of positions) are allowed for these. A given player thus could be a member of one or more position groups. Similarly, doubleheaders may be allowed, in which case a player may appear in either of 2 games. This can be accommodated via a redefinition of the features.
In most cases, we’ll want the non-primary features to be partitions if possible. We may need some creativity in defining them, however. For example, consider the two constraints in the Classic tournament described above. Hitter vs pitcher isn’t a natural feature. Moreover, the constraint seems to rely on two distinct features. There is no rule against this, of course. But we can make it a more efficient single-feature constraint by defining a new feature with 31 groups: one containing all the pitchers from all teams, and the other 30 containing hitters from each of the 30 real teams. We then simply require that there be no more than 5 items in any group of this new feature. Because only 2 pitchers are picked anyway, the 31st group never would be affected.
Our reference implementation allows for general user-defined constraints via a functionoid, but we also provide two concrete constraint classes. With a little cleverness, these two cover all the cases which arise in Fantasy Sports. Both concern themselves with a single feature, which must be a partition:
- Require items from at least
groups. It is easy to see that the
- Allow at most
hitter per team constraints fit this mold.
When designing custom constraints, it is important to seek an efficient implementation. Every collection which passes the primary pruning will be tested against every constraint. Pre-computing a specialized feature is a good way to accomplish this.
— Sample Setup for DraftKings Classic Fantasy Baseball Tournament —
How would we configure our system for a real application? Consider the Classic Fantasy Baseball Tournament described above.
The player information may be provided in many forms, but for purposes of exposition we will assume we are handed vectors, each of the correct length and with no null or bad values. We are given the following:
- A roster of players available in the given tournament. This would include players from all teams playing that day. Each team would include hitters from the starting lineup, as well as the starting pitcher and one or more relief pitchers. We’ll say there are
players, listed in some fixed order for our purposes.
denotes player
in our listing.
- A set
of games represented in the given tournament. This would be all the games played on a given day. Almost every team plays each day of the season, so this is around 15 games. We’ll ignore the 2nd game of doubleheaders for our purposes (so a given team and player plays at most once on a given day).
- A set
of teams represented in the given tournament. This would be all 30 teams.
- A vector
of length
- A vector
of length
- A vector
of length
- A vector
of length
- A vector
of length
Note that DraftKings provides all this info (though they may have to be munged into some useable form), except the model prediction.
We now define a new vector 
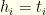
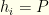

Next, we map the values of 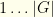

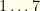
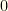
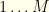
From this, we pass the following to our algorithm:
- Number of items:
- Size of a collection:
- Feature 1:
groups (the positions), and marked as a partition.
- Feature 2:
groups (the teams), and marked as a partition.
- Feature 3:
groups (the games), and marked as a partition.
- Feature 4:
groups (the teams for hitters plus a single group of all pitchers), and marked as a partition.
- Primary Feature: Feature 1
- Primary Feature Group Counts:
(i.e. P,P,C,1B,2B,3B,SS,OF,OF,OF)
- Item costs:
- Item values:
- Item Feature 1 Map:
(i.e.
)
- Item Feature 2 Map:
(i.e.
- Item Feature 3 Map:
(i.e.
- Item Feature 4 Map:
(i.e.
)
- Cost Cap:
- Constraint 1: No more than
items in any one group of Feature 4. (i.e.
- Constraint 2: Items from at least
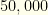
Strictly speaking, we could have dispensed with Feature 2 in this case (we really only need the team through Feature 4), but we left it in for clarity.
Note that we also would pass certain tolerance parameters to the algorithm. These tune its aggressiveness as well as the number of teams potentially returned.
— Algorithm —
— Culling of Individual Items —
First, we consider each group of the primary feature and eliminate strictly inferior items. These are items we never would consider picking because there always are better choices. For this purpose we use a tolerance parameter, 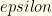
- Restrict ourselves only to items which are unique to that group. I.e., if an item appears in multiple groups it won’t be culled.
- Scan the remaining items in descending order of value. For item
and value
- Scan over all items
- If there are
then we cull item
- Scan over all items
So basically, it’s simple comparison shopping. We check if there are enough better items at the same or lower cost. If so, we never would want to select the item. We usually don’t consider “strictly” better, but allow a buffer. The other items must be sufficiently better. There is a rationale behind this which will be explained shortly. It has to do with the fact that the cull stage has no foreknowledge of the delicate balance between ancillary constraints and player choice. It is a coarse dismissal of certain players from consideration, and the tolerance allows us to be more or less conservative in this as circumstance dictates.
If a large number of items appear in multiple groups, we also can perform a merged pass — in which those groups are combined and we perform a constrained cull. Because we generally only have to do this with pairs of groups (ex. a “flex” group and each regular one), the combinatorial complexity remains low. Our reference implementation doesn’t include an option for this.
To see the importance of the initial cull, consider our baseball example but with an extra 2 players per team assigned to a “flex” position (which can take any player from any position). We have 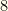

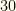
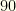

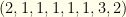
The size of the overall state space is around 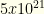
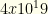



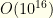
Thus we see the importance of this initial cull. Even if we have to perform a pairwise analysis for a flex group — and each paired cull costs 

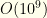
One important word about this cull, however. It is performed at the level of individual primary-feature groups. While it accommodates the overall cost cap and the primary feature group allocations, it has no knowledge of the ancillary constraints. It is perfectly possible that we cull an item which could be used to form the highest value admissible collection once the ancillary constraints are taken into account. This is part of why we use the tolerance 
We note that in fantasy sports, the ancillary constraints are weak in the sense that they affect a small set of collections and these collections are randomly distributed. I.e, we would have to conspire for them to have a meaningful statistical effect. We also note that there tend to be many collections within the same tiny range of overall value. Since the item value model itself inherently is statistical, the net effect is small. We may miss a few collections but they won’t matter. We’ll have plenty of others which are just as good and are as statistically diverse as if we included the omitted ones.
In general use, we may need to be more careful. If the ancillary constraints are strong or statistically impactful, the initial cull may need to be conducted with care. Its affect must be measured and, in the worst case, it may need to be restricted or omitted altogether. In most cases, a well-chosen
In practice,
Another approach to accommodating flex groups or avoiding suboptimal results due to the constraints is to require more than the selection count when culling in a given group. Suppose we need to select 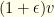




One final note. If a purely lossless search is required then the individual cull must be omitted altogether. In the code this is accomplished by either choosing
— Prepare for Search —
We can think of our collection as a selection of 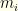


For the search itself we iterate by group, then within each group. Conceptually, this could be thought of as a bunch of nested loops from left group to right group. In practice, it is best implemented recursively.
We can precompute certain important information:
- Each group has
possible selections. We can precompute this easily enough.
- We also can compute
. I.e. the product of the total combinations of this group and those that come after.
-
is the sum of the top
-
is
. I.e., the best total value we can get from all subsequent groups.
-
is the sum of the bottom
-
is
. I.e., the cheapest we can do for all subsequent groups, if value is no concern.
- Sorted lists of the items by value and by cost.
- Sorted lists of
The search itself depends on two key iteration decisions. We discuss their effects on efficiency below.
- Overall, do we scan the groups from fewest to most combinations (low to high
) or from most to fewest (high to low
- Within each group, do we scan the items from lowest to highest cost or from highest to lowest value. Note that of the four possible combinations, the other two choices make no sense. It must be one of these.
Based on our choice, we sort our groups, initialize our counters, and begin.
— Search —
We’ll describe the search recursively.
Suppose we find ourselves in group 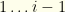

We need to cycle over all 
We now discuss the individual iteration. For each step we compute the following:
-
is the minimum cost of all remaining groups (
onward). This is the lowest cost we possibly could achieve for subsequent groups. It is the pre-computed
-
is the maximum value of all remaining groups (
-
is the cost of our current selection for group
-
is the value of our current selection for group
Next we prune if necessary. There are 2 prunings, the details of which depend on the type of iteration.
If we’re looping in increasing order of cost:
- If
then there is no way to select from the remaining groups and meet the cost cap. Worse, all remaining iterations within group
- If
then there is no way to select a high enough value collection from the remaining groups. However, it is possible that other iterations may do so (since we’re iterating by cost, not value). We prune just the current selection, and move on to the next combo in group
If on the other hand we’re looping in decreasing order of value, we do the opposite:
- If
- If
If we get past this, our combo has survived pruning. If 
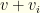
If on the other hand, we are the last group, then we have a completed collection. Now we must test it.
If we haven’t put any protections against the same item appearing in different slots (if it is in multiple groups), we must test for this and discard the collection if it is. Finally, we must test it against our ancillary constraints. If it violates any, it must be discarded. What do we do with collections that pass muster? Well, that depends. Generally, we want to limit the number of collections returned to some number 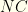
If our new collection exceeds all others in value, we update 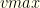
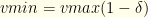

I.e., we keep at most
And that’s it.
— Tuning —
Let’s list all the user-defined tunable parameters and choices in our algorithm:
- What is the individual cull tolerance
?
- What is
- Do we scan the groups from fewest to most combinations or the other way?
- Within each group, do we scan the items from lowest to highest cost or from highest to lowest value?
- What is the maximum number of collections
we report back (or do we keep them all)?
- What is the collection value tolerance
?
Clearly, 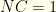

The details of post-cull search performance will depend heavily on the primary partition structure and cost distribution, as well as our 2 search order choices. The following is a simple test comparison benchmark (using the same data and the 
| GroupOrder | CombosOrder | Time | Analyzed |
| Value high-to-low | high-to-low | 12.1s | 7.9MM |
| Value high-to-low | low-to-high | 3.4s | 1.5MM |
| Cost low-to-high | high-to-low | 69.7s | 47.5MM |
| Cost low-to-high | low-to-high | 45.7s | 18.5MM |
Here, “Analyzed” refers to the number of collections which survived pruning and were tested against the ancillary constraints. The total number of combinations pruned was far greater.
Of course, these numbers mean nothing in an absolute sense. They were run with particular test data on a particular computer. But the relative values are telling. For these particular conditions, the difference between the best and worst choice of search directions was over