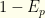Now that Covid-19 rapid home tests are widely available, it is important to consider how to interpret their results. In particular, I’m going to address two common misconceptions.
To keep things grounded, let’s use some actual data. We’ll assume a false positive rate of 1% and a false negative rate of 35%. These numbers are consistent with a March, 2021 metastudy [1]. We’ll denote the false positive rate 
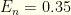
It may be tempting to assume from these numbers that a positive rapid covid test result means you’re 99% likely to be infected, and a negative result means you’re 65% likely not to be. Neither need be the case. In particular,
- A positive result does increase the probability you have Covid, but by how much depends on your previous prior. This in turn depends on how you are using the test. Are you just randomly testing yourself, or do you have some strong reason to believe you may be infected?
-
A negative result has little practical impact on the probability you have Covid.
These may seem counterintuitive or downright contradictory. Nonetheless, both are true. They follow from Bayes’ thm.
Note that when I say that the test increases or decreases “the probability you have Covid,” I refer to knowledge not fact. You either have or do not have Covid, and taking the test obviously does not change this fact. The test simply changes your knowledge of it.
Also note that the limitations on inference I will describe do not detract from the general utility of such tests. Used correctly, they can be extremely valuable. Moreover, from a behavioral standpoint, even a modest non-infinitesimal probability of being infected may be enough to motivate medical review, further testing, or self-quarantine.
Let’s denote by 


If you have no information and are conducting a random test, then it may be reasonable to use the general local infection rate as
The test adds information to your prior 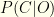
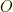
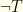
In our notation, 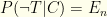



What we care about are the posterior probabilities: (1) the probability 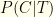
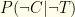
Bayes’ Thm tells us that 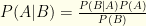
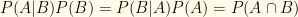
If you test positive, what is the probability you have Covid? 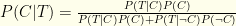

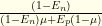
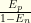
Suppose you randomly tested yourself in MA. According to data from Johns Hopkins [2], at the time of this writing there have been around 48,000 new cases reported in MA over the last 28 days. MA has a population of around 7,000,000. It is reasonable to assume that the actual case rate is twice that reported (in the early days of Covid, the unreported factor was much higher, but let’s assume it presently is only 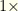
Le’ts also assume that any given case tests positive for 14 days. I.e., 24,000 of those cases would test positive at any given time in the 4 week period (of course, not all fit neatly into the 28 day window, but if we assume similar rates before and after, this approach is fine). Including the unreported cases, we then have 48,000 active cases at any given time. We thus have a state-wide infection rate of 

Using this prior, a positive test means you are 
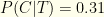
This may seem terribly counterintuitive. After all, the test had a 1% false positive rate. Shouldn’t you be 99% certain you have Covid if you test positive? Well, suppose a million people take the test. With a 0.00685 unconditional probability of infection, we expect 6850 of those people to be infected.
However, even with a tiny false positive rate of 
Returning to the general case, suppose you test negative. What is the probability you do not have Covid? 


Under 
This too may seem counterintuitive. As an analogy, suppose in some fictional land earthquakes are very rare. Half of them are preceded by a strong tremor the day before (and such a tremor always heralds a coming earthquake), but the other half are unheralded.
If you feel a strong tremor, then you know with certainty than an earthquake is coming the next day. Suppose you don’t feel a strong tremor. Does that mean you should be more confident that an earthquake won’t hit the next day? Not really. Your chance of an earthquake has not decreased by a factor of two. Earthquakes were very rare to begin with, so the default prediction that there wouldn’t be one only is marginally changed by the absence of a tremor the day before.
Of course,
Graphs 1 and 2 below illustrate the information introduced by a positive or negative test result as a function of the choice of prior. In each, the difference in probability is the distance between the posterior and prior graphs. The prior obviously is a straight line since we are plotting it against itself (as the 
From graph 1, it is clear that except for small priors (such as the general infection rate in an area with very low incidence), a positive result adds a lot of information. For 
From graph 2, we see that a negative result never adds terribly much information. When the prior is 1 or 0, we already know the answer, and the Bayesian update does nothing. The largest gain is a little over 0.2, but that’s only attained when the prior is quite high. In fact, there’s not much improvement at all until the prior is over 0.1. If you’re 10% sure you already have covid, a home test will help but you probably should see a doctor anyway.
Note that these considerations are less applicable to PCR tests, which can have sufficiently small
One last point should be addressed. How can tests with manufacturer-specific false positive and false negative rates depend on your initial guess at your infection probability? If you pick an unconditional local infection rate as your prior, how could they depend on the choice of locale (such as MA in our example)? That seems to make no sense. What if we use a smaller locale or a bigger one?
The answer is that the outcome of the test does not depend on such things. It is a chemical test being performed on a particular sample from a particular person. Like any other experiment, it yields a piece of data. The difference arises in what use we make of that data. Bayesian probability tells us how to incorporate the information into our previous knowledge, converting a prior to a posterior. This depends on that knowledge — i.e. the prior. How we interpret the result depends on our assumptions.
A couple of caveats to our analysis:
- The irrelevance of a negative result only applies when you have no prior information other than some (low) general infection rate. If you do have symptoms or have recently been exposed or have any other reason to employ a higher prior probability of infection, then a negative result can convey significantly more information. Our dismissal of its worth was contingent on a very low prior.
-
Even in the presence of a very low prior probability of infection, general testing of students or other individuals is not without value. Our discussion applies only to the interpretation of an individual test result. In aggregate, the use of such tests still would produce a reasonable amount of information. Even if only a few positive cases are caught as a result and the overall exposure rate is lowered only a little, the effect can be substantial. Pathogen propagation is a highly nonlinear process, and a small change in one of the parameters can have a very large effect. One caution, however. If the results aren’t understood for what they are, overconfidence can result. The aggregate use of testing can have a substantial negative effect if it results in relaxation of other precautions due to overconfidence resulting from a misunderstanding of the information content of those test results.


References:
[1] Rapid, point‐of‐care antigen and molecular‐based tests for diagnosis of SARS‐CoV‐2 infection — Dinnes, et al. Note that “specificity” refers to