Book Production Framework and Examples on GitHub
Introduction
Over the last couple of years, a number of people have asked me how I produce my books. Most self-published (excuse me, ‘indie-published’) books have an amateurish quality that is easy to spot, and the lack of attention to detail detracts from the reading experience. Skimping on cover art can be a culprit, but it rarely bears sole blame — or even the majority of it. Indie-published interiors often are sloppy, even in books with well-designed covers. For some reason, many authors give scant attention to the interior layout of their books. Of course, professional publishers know better. People judge books not just by their covers, but by their interiors as well. If the visual appeal of your book does not concern you, then read no further. Your audience most likely will not.
Producing a visually-pleasing book is not an insurmountable problem for the indie-publisher, nor a particularly difficult one. It just requires a bit of attention. Even subject to the constraints of print-on-demand publishing, it is quite possible to produce beautiful looking books. Ebooks prove more challenging because one has less control over them (due to the need for reflowable text), but it is possible to do as well as the major publishers by using some of their tricks. Moreover, all this can be accomplished from the command-line and without the use of proprietary software.
Now that I’ve finished my fifth book of fiction (and second novel), I figure it’s a good time to describe how I produce my books. I have automated almost the entire process of book and ebook production from the command-line. My process uses only free, open-source software that is well-established, well-documented, and well-maintained.
Though I use Linux, the same toolchain could be employed on a Mac or Windows box with a tiny bit of adaptation. To my knowledge, all the tools I use (or obvious counterparts) are available on both those platforms. In fact, MacOS is built on a flavor of unix, and the tools can be installed via Homebrew or other methods. Windows now has a unix subsystem which allows command-line access as well.
I have made available a full implementation of the system for both novels and collections of poetry, stories, or flash-fiction. Though I discuss some general aspects below, most of the nitty gritty appears in the github project’s README file and in the in-code documentation. The code is easily adaptable, and you should not feel constrained to the design choices I made. The framework is intended as a proof of concept (though I use it regularly myself), and should serve as a point of departure for your own variant. If you encounter any bugs or have any questions, I encourage you to get in touch. I will do my best to address them in a timely fashion.
Examples
First, let’s see some examples of output (unfortunately, wordpress does not allow epub uploads, but you can generate epubs from the repository and view them in something like Sigil). The novel and collection pdfs are best viewed in dual-page mode since they have a notion of recto and verso pages.
Who would be interested in this
If you’re interested in producing a fiction book from the command-line, it is fair to assume that (1) you’re an author or aspiring author and (2) you’re at least somewhat conversant with shell and some simple scripting. For scripting, I use Python 3, but Perl, Ruby, or any comparable language would work. Even shell scripting could be used.
At the time of this writing, I have produced a total of six books (five fiction books and one mathematical monograph) and have helped friends produce several more. All the physical versions were printed through Ingram, and the ebook versions were distributed on Amazon. Ingram is a major distributor as well, so the print versions also are sold through Amazon, Barnes & Noble, and can be ordered through other bookstores. In the past I used Smashwords to port and distribute the ebook through other platforms (Kobi, Barnes & Noble, etc), but frankly there isn’t much point these days unless someone (ex. Bookbub) demands it. We’re thankfully past the point where most agents and editors demand Word docs (though a few still do), but producing one for the purpose of submission is possible with a little adaptation using pandoc and docx templates. However, most people accept PDFs these days.
My books so far include two novels, three collections of poetry & flash-fiction, and a mathematical monograph. I have three other fiction books in the immediate pipeline (another collection of flash-fiction, a short story collection, and a fantasy novel), and several others in various stages of writing. I do not say this to toot my own horn, but to make clear that the method I describe is not speculative. It is my active practice.
The main point of this post is to demonstrate that it is quite possible to produce a beautiful literary book using command-line, open-source tools in a reproducible way. The main point of the github project is to show you precisely how to do so. In fact, not only can you produce a lovely book that way, but I would argue it is the best way to go about it! This is true whether your book is a novel or a collection of works.
One reason why such a demonstration is necessary is the dearth of online examples. There are plenty of coding and computer-science books produced from markdown via pandoc. There are plenty of gorgeous mathematics books produced using LaTeX. But there are very few examples in the literary realm, despite the typesetting power of LaTeX, and the presence of the phenomenal Memoir LaTeX class for precisely this purpose. This post is intended to fill that gap.
A couple of caveats.
Lest I oversell, here are a couple of caveats.
- When I speak of an automated build process, I mean for the interiors of books. I hire artists to produce the covers. Though I have toyed with creating covers from the command-line in the past (and it is quite doable), there are reasons to prefer professional help. First, it allows artistic integration of other cover elements such as the title and author. Three of my books exhibit such integration, but I added those elements myself for the rest (mainly because I lacked the prescience to request them when I commissioned the art early on). I’ll let you guess which look better. The second big reason to use a professional artist comes down to appeal. The book cover is the first thing to grab a potential reader’s eye, and can make the sale. It also is a key determinant in whether your book looks amateurish or professional. I am no expert on cover design, and am far from skilled as an artist. A professional is much more likely to create an appealing cover. Of course, plenty of professionals do schlocky work, and I strongly advise putting in the effort and money to find a quality freelancer. In my experience, it should cost anywhere from $300-800 in today’s dollars. I’ve paid more and gotten less, and I’ve paid less and gotten more. My best experiences were with artists who did not specialize in cover design.
- The framework I provide on github is intended as a guide, not as pristine code for commercial use. I am not a master of any of the tools involved. I learned them to the extent necessary and no more. I make no representation that my code is elegant, and I wouldn’t be surprised if you could find better and simpler ways to accomplish the same things. This should encourage rather than discourage you from exploring my code. If I can do it, so can you. All you need is basic comfort with the command-line and some form of scripting. All the rest can be learned easily. I did not have to spend hundreds of hours learning Python, make, pandoc, and so on. I learned the basics, and googled whatever issues arose. It was quite feasible, and took a tiny fraction of the time involved in writing a novel.
The benefits of a command-line approach
If you’ve come this far, I expect that listing the benefits of a command-line approach is unnecessary. They are roughly the same as for any software project: stability, reproducibility, recovery, and easy maintenance. Source files are plain text, and we can bring to bear a huge suite of relevant tools.
A suggestion vis-a-vis code reuse
One suggestion: resist the urge to unify code. Centralizing scripts to avoid code duplication or creating a single “universal” script for all your books may be enticing propositions. I am sorely tempted to do so whenever I start a new project. My experience is that this wastes more time than it saves. Each project has unforeseeable idiosyncrasies which require adaptation, and changing centralized or universal scripts risks breaking backward compatibility with other projects. By having each book stand on its own, reproducibility is much easier, and we are free to customize the build process for a new book without fear of unexpected consequences. It also is easier to encapsulate the complete project for timestamping and other purposes. It’s never pleasant to discover that a backup of your project is missing some dependency that you forgot to include.
A typical author produces new books or revises old ones infrequently. The ratio of time spent maintaining the publication machinery to writing and editing the book is relatively small. On average, it takes me around 500 hours to write and edit a 100,000 word novel, and around 100 hours for a 100 page collection of flash-fiction and poetry. Adapting the framework from my last book typically takes only a few hours, much of which is spent on adjustments to the cover art.
Even if porting the last book’s framework isn’t that time consuming, why trouble with it at all? Why not centralize common code? The problem is that this produces a dependency on code outside the project. If we change the relevant library or script, then we must worry about the reproducibility of all past books which depend on it. This is a headache.
Under other circumstances, my advice would be different. For example, a small press using this machinery to produce hundreds of books may benefit from code unification. The improved maintainability and time savings from code centralization would be significant. In that case, backward-compatibility issues would be dealt with in the same manner as for software: through regression tests. These could be strict (MD5 checksums) or soft (textual heuristics) depending on the toolchain and how precise the reproducibility must be. For example, non-visual changes such as an embedded date would alter the hash but not textual heuristics. The point is that this is doable, but would require stricter coding standards and carefully considered change-metrics.
The other reason to avoid code reuse is the need for flexibility. Unanticipated issues may arise with new projects (ex. unusually formatted poems), and your stylistic taste may change as well. You also may just want to mix things up a bit, so all your books don’t look the same. Copying the framework to a new book would be done a few times a year at most, and probably far less.
Again, if the situation is different my advice will be too. For example, a publisher producing books which vary only in a known set of layout parameters may benefit from a unified framework. Even in this case, it would be wise to wait until a number of books have been published, to see which elements need to be unified and which parameters vary book to book.
Tools
Here is a list of some tools I use. Most appear in the project but others serve more of a support function.
Core tools
- pandoc: This is used to convert from markdown to epub and LaTeX. It is an extremely powerful conversion tool written in Haskell. It often requires some configuration to get things to work as desired, but it can do most of what we want. And no, you do not need to know Haskell to use it.
- make: The entire process is governed by a plain old Makefile. This allows complete reproducibility.
- pdfLaTeX: The interior of the print book is compiled from LaTeX into a pdf file via pdfLaTeX. LaTeX affords us a great way to achieve near-total control over the layout. You need not know much LaTeX unless extensive changes to the interior layout are desired. The markdown source text is converted via pandoc to LaTeX through templates. These templates contain the relevant layout information.
- memoir LaTeX class: This is the LaTeX class I use for everything. It is highly customizable, relatively easy to use, and ideally suited to book production. It has been around for a long time, is well-maintained, has a fantastic (albeit long) manual, and boasts a large user community. As with LaTeX, you need not learn its details unless customization of the book layout is desired. Most simple things will be obvious from the templates I provide.
Essential Programs, but can be swapped with comparables
- python3: I write my scripts in python 3, but any comparable scripting language will do.
- aspell: This is the command-line spell-checker I use, but any other will do too. It helps if it has a markdown-recognition mode.
- emacs: I use this as my text editor, but vim or any other text editor will do just fine. As long as it can output plain text files (ascii or unicode, though I personally stick to ascii) you are fine. I also use emacs org-mode for the organizational aspects of the project. One tweak I found very useful is to have the editor highlight anything in quotes. This makes conversation much easier to parse when editing.
- pdftools (poppler-utils): Useful tools for splitting out pages of pdfs, etc. Used for ebook production. I use the pdfseparate utility, which allows extraction of a single page from a PDF file. Any comparable utility will work.
Useful Programs, but not essential
- git: I use this for version control. Strictly speaking, version control isn’t needed. However, I highly recommended it. From a development standpoint, I treat writing as I do a software project. This has served me well. Any comparable tool (such as mercury) is fine too. Note that the needs of an author are relatively rudimentary. You probably won’t need branching or merging or rebasing or remote repos. Just “git init”, “git commit -a”, “git status”, “git log”, “git diff”, and maybe “git checkout” if you need access to an old version.
- wdiff, color-diff: I find word diff and color-diff very useful for highlighting changes.
- imagemagick: I use the “convert” tool for generating small images from the cover art. These can be used for the ebook cover or for advertising inserts in other books. “identify” also can be useful when examining image files.
- pdftk (free version): Useful tools for producing booklets, etc. I don’t use it in this workflow, but felt it was worth mentioning.
- ebook-convert: Calibre command-line tool for conversion. Pandoc is far better than calibre for most conversions, in my experience. However, ebook-convert can produce mobi and certain other ebook formats more easily.
- sigil: This the only non-command-line tool listed, but it is open-source. Before you scoff and stop reading, let me point out that this is the aforementioned “almost” when it comes to automation. However, it is a minor exception. Sigil is not used for any manual intervention or editing. I simply load the epub which pandoc produces into sigil, click an option to generate the TOC, and then save it. The reason for this little ritual is that Amazon balks at the pandoc-produced TOC for some reason, but seems ok with Sigil’s. It is the same step for every ebook, and literally takes 1 minute. Unfortunately, sigil offers no command-line interface, and there is no other tool (to my knowledge) to do this. Sigil also is useful to visually examine the epub output if you wish. I find that it gives the most accurate rendering of epubs.
- eog: I use this for viewing images, though any image viewer will do. It may be necessary to scale and crop (and perhaps color-adjust) images for use as book covers or interior images. imageMagick’s “identify” and “convert” commands are very useful for such adjustments, and eog lets me see the results.
How I write
All my files are plain text. I stick to ascii, but these days unicode is fine too. However, rich-text is not. Things like italics and boldface are accomplished through markdown.
Originally, I wrote most of my pieces (poems, chapters, stories) in LaTeX, and had scripts which stitched them together into a book or produced them individually for drafts or submissions to magazines. These days, I do everything in markdown — and a very simple form of markdown at that.
Why not just stick with LaTeX for the source files? It requires too much overhead and gets in the way. For mathematical writing, this overhead is a small price to pay, and the formatting is inextricably tied to the text. But for most fiction and poetry, it is not.
I adhere to the belief that separating format and content is a wise idea, and this has been borne out by my experience. Some inline formatting is inescapable (bold, italics, etc), and markdown is quite capable of accommodating this. On the rare occasions when more is needed (ex. a specially formatted poem), the markdown can be augmented with html or LaTeX directly as desired. Pandoc can handle all this and more. It is a very powerful program.
I still leave the heavy formatting (page layout, headers, footers, etc) to LaTeX, but it is concentrated in a few templates, rather than the text source files themselves.
There also is another reason to prefer markdown. From markdown, I more easily can generate epubs or other formats. Doing so from LaTeX is possible but more trouble than it’s worth (I say this from experience).
What all this means is that I can focus on writing. I produce clear, concise ascii files with minimal format information, and let my scripts build the book from these.
To see a concrete example, as well as all the scripts involved, check out the framework on github.
 and the false negative rate
and the false negative rate 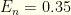 .
.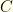 the event of having Covid, and by
the event of having Covid, and by  the event of testing positive for it.
the event of testing positive for it.  is the prior probability of having covid. It is your pre-test estimate based on everything you know. For convenience, we’ll often use
is the prior probability of having covid. It is your pre-test estimate based on everything you know. For convenience, we’ll often use 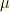 to denote
to denote 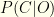 , where
, where 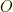 denotes the outcome of the test: either
denotes the outcome of the test: either 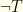 .
.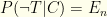 and
and  . These numbers are properties of the test, independent of the individuals being tested. For example, the manufacturer could test 1000 swabs known to be infected with covid from a petri dish, and
. These numbers are properties of the test, independent of the individuals being tested. For example, the manufacturer could test 1000 swabs known to be infected with covid from a petri dish, and  would be the number which tested negative divided by 1000. Similarly, they could test 1000 clean swabs, and
would be the number which tested negative divided by 1000. Similarly, they could test 1000 clean swabs, and  would be the number which tested positive divided by 1000.
would be the number which tested positive divided by 1000.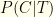 that you are infected given that you tested positive, and (2) the probability that you are not infected given that you tested negative
that you are infected given that you tested positive, and (2) the probability that you are not infected given that you tested negative 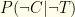 . I.e. the probabilities that the test correctly reflects your infection status.
. I.e. the probabilities that the test correctly reflects your infection status.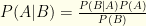 , a direct consequence of the fact that
, a direct consequence of the fact that 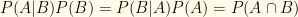 .
.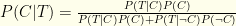 , which is
, which is  . The prior of infection was
. The prior of infection was 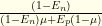 . For
. For 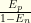 .
. ).
). , or about 0.7%. We will define
, or about 0.7%. We will define  .
. more likely to be infected post-test than pre-test. This seems significant! Unfortunately, the actual probability is
more likely to be infected post-test than pre-test. This seems significant! Unfortunately, the actual probability is 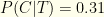 .
. .
. . For small
. For small  unless
unless  .
. as the prior, the probability of being uninfected post-test is 0.99757 vs 0.9932 pre-test. For all practical purposes, our knowledge has not improved.
as the prior, the probability of being uninfected post-test is 0.99757 vs 0.9932 pre-test. For all practical purposes, our knowledge has not improved. -axis). Note that graph 1 has an abbreviated
-axis). Note that graph 1 has an abbreviated  , it provides near certainty of infection.
, it provides near certainty of infection.

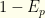 and “sensitivity” refers to
and “sensitivity” refers to  . See
. See 